G
Gelöschtes Mitglied 35125
Gast
hallo leute,
vor kurzem habe ich mich für ein praktikum beworben und habe auch schon eine antwort wo ich aufgefordert werde ein web crawler in java zu schreiben.
der web crawler soll folgendes können:
-den inhalt einer webseite holen
-aus dem inhalt die links extrahieren
-die extrahierten links crawlen(zurück zu step 1)
-bei 1000 links schluss machen
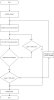
da ich noch keinen plan von webcrawlern hatte war ich erstmal ein wenig baff, habe mich nu erstmal schlau gemacht und ein flussdiagramm erstellt um zu gucken ob ich die sache kapiert habe. ich will nichts großes programmieren, halt nur ein crawler der den o.g. anforderungen entspricht.
ich habe also vor diesen thread als eine art mindmap zu nutzen wo ihr mir hoffentlich auch ein paar kommentare/kritik/tipps geben könntet
gibt für crawler schon klassen? also womit man aus html-dokumenten die url & links rausfiltern kann?
hab das flussdiagramm als anhang beigefügt, hoffe dass ich da keine fehler gemacht habe...
greetz
vor kurzem habe ich mich für ein praktikum beworben und habe auch schon eine antwort wo ich aufgefordert werde ein web crawler in java zu schreiben.
der web crawler soll folgendes können:
-den inhalt einer webseite holen
-aus dem inhalt die links extrahieren
-die extrahierten links crawlen(zurück zu step 1)
-bei 1000 links schluss machen
da ich noch keinen plan von webcrawlern hatte war ich erstmal ein wenig baff, habe mich nu erstmal schlau gemacht und ein flussdiagramm erstellt um zu gucken ob ich die sache kapiert habe. ich will nichts großes programmieren, halt nur ein crawler der den o.g. anforderungen entspricht.
ich habe also vor diesen thread als eine art mindmap zu nutzen wo ihr mir hoffentlich auch ein paar kommentare/kritik/tipps geben könntet
gibt für crawler schon klassen? also womit man aus html-dokumenten die url & links rausfiltern kann?
hab das flussdiagramm als anhang beigefügt, hoffe dass ich da keine fehler gemacht habe...
greetz