Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder ein alternativer Browser verwenden.
Es bezweifelt ja auch niemand, dass man auf diese Weise ein funktionsfähiges Programm erstellen kann. Man wird nur hinsichtlich Eintwicklungsaufwand und Performance ineffizienter. Je größer die Anwendung wird, desto intensiver werden diese Probleme in Erscheinung treten. Welche Vorteile bekommt man dafür?
Ich vermute, du meinst oben mit "Skalierbarkeit" eigentlich Flexibilität hinsichtlich des Hinzufügens zusätzlicher Datenfelder und siehst darin die Vorteile. Da sollte man unterscheiden, ob es darum, dass der Entwickler oder der Anwender sie hinzufügt.
Für den Entwickler würde das bedeuten, dass er die neuen Datenfelder nicht mit den Werkzeugen des DBMS einbaut, sondern in deine Tabellenstruktur. Im ersten Fall liefert ihm das DBMS die Werkzeuge dafür, im zweiten Fall mußt du sie erst programmieren. In beiden Fällen muß er sich aber darum kümmern und spart keine Arbeit.
Wenn der Anwender die Möglichkeit bekommen soll, eigene Datenfelder zu erstellen, geht das nur über eine Tabellensteuerung, denn er hat natürlich keinen Zugriff auf die Verwaltungsfunktionen der DB. Aber das muß der Entwickler doch auch bei deinem Ansatz entsprechend vorsehen. Es muß ja irgendwo definiert werden, was mit welchen Informationen gemacht werden soll. Das ist nicht mit dem Einfügen in eine Mastertabelle erledigt.
Wie früher schon einmal erwähnt, ist das Abbilden von Sachmerkmalen oder Klassifizierungen ein Anwendungsfall, für den ähnliche Strukturen gut funktionieren. Das ist dann aber auch nur Bestandteil der Normalisierungen des normalen Relationenkonzepts.
Ja dann muss man sich gute Suchalgorithmen ausdenken, was bei Maria DB schon gut gelöst ist.
Ach wisst ihr was: sollte der Shop zu langsam werden, implementiere ich ladebalken für längere vorgänge, es ist spannend zuzusehen wenn etwas passiert. Man freut sich auf so ein "Progress".
Man kann ja auch Datensätze auf die ganz lange nicht zugegriffen wurde in eine andere Tabelle archivieren.
Ich habe auch ganz Normal angefangen: erstmal Benutzer-Verwaltung (Extra Tabelle für Benutzer) Produkte-Verwaltumg, habe sogar eine Bilder-Gallerie gemacht mit zusätzlicher Tabelle. Und habe immer gemerkt, dass die dinger sich wiederholen:
Man muss für das Löschen eines Elements (Bild, Produkt, Benutzer) eigene Routine schreiben, da alle Tabellen anders sind.
In dem Shop ist es praktisch die Produkte zu Kategorisieren. So machte ich auf ähnliche weise eine extra Tabelle für Kategorien. Und dann ist mir die Baumstruktur aufgefallen: Man kann in so einen Baum alles Speichern.
Dann wollte ich auch Attribute beliebig definieren können, so dass sich die Produkte Ihre Kategorienattribute vererben (In der Kategorie "Monitore" soll jedes element "Bildschirmauflösung" haben.
In einer MySQL Datenbank arbeitest du nicht einfach mit "Elementen", sondern mit konkreten Spalten / Feldern.
Und natürlich ist keine Tabelle gleich, das würde auch gar keinen Sinn ergeben!
Die Tabellen sind nicht abstrakt, sondern konkret. Man kann es mit der Mathematik vergleichen, ein Mathematiker denkt sich was wunderschönes, theoretisches aus, was seiner Meinung nach super aussieht und funktionieren müsste, aber der eher praktisch orientierte Informatiker (in den meisten Unis mittlerweile Ingeneurswissenschaft) kann es fast nie 1 : 1 so implementieren - eben weil es zwar so toll aussieht, aber entweder nicht lösbar (begrenzte Rechenresourcen) oder nicht performant wäre.
In der Geschichte haben Naturwissenschaftler etwas entdeckt / erforscht, aber erst ein Ingeneur konnte das effizient nutzbar machen, z.B. bei der Dampfmaschine. Das ist eben der große Unterschied zwischen Theorie und Praxis.
Auch das Smartphone gab es schon lange, bevor Apple es "erfand", aber Apple hat es geschafft, das Smartphone so zu gestalten, dass es für den Otto-Normal-Verbraucher interessant wurde.
Nun aber genug abgeschweift, zurück zum Thema:
Für jede Tabelle eine Routine zu schreiben (ich hoffe du meinst damit keine MySQL Routine!) macht das ganze eben performant.
Wenn du folgende Tabelle hast (habs jetzt nicht validiert / getestet):
Und du von dem Namen "neoexpert" die ID wissen willst, dann schreibst du folgenden Query:
Code:
SELECT * FROM `test_table` WHERE `name` = 'neoexpert';
MySQL sucht danach nach dem String neoexpert nur in der Spalte "name" und nicht überall (!) und liefert dir dann die ganze Zeile zurück. Da ich einen Index gesetzt habe, hat MySQL intern neben der normalen Datei noch eine Datei angelegt, wo "name - Zeilennummer" steht, sodass MySQL die Spalte "name" sehr schnell und performant suchen und finden kann.
In deinem Beispiel würde MySQL aber ebenfalls alle Einträge von "prename" und "mail" mit durchgehen müssen, da diese ja in der selben Tabelle und der selben Spalte stehen. Und genau dies ist nicht performant, da MySQL hierbei 4x so viele Daten durchsuchen müsste.
Bäume sind optimiert darauf, Werte auf genau 1 Key zu suchen - MySQL hat aber nicht nur 1 Key!
Du willst ja nicht nur die Zeile über die ID, sondern ebenfalls über die Spalte "name" direkt suchen können.
Und genau das können die meisten dokument-orientierten NoSQL Datenbanken (z.B. MongoDB) ebenfalls nicht wirklich effizient, weil es nicht deren Ziel ist! Relationen sind nicht wirklich gut skalierbar, weil sie genau deshalb so viele Abhängigkeiten besitzen, aber MySQL ist eben auch nicht für Big Data ausgelegt. Und MongoDB ist auch eher dafür ausgelegt, nach einem bestimmten Key zu suchen (sagt mir, wenn ich mich irre!), auch wenn man nach Spalten suchen kann. Wenn du einen einfachen Key-Value-Store hättest, wäre nen Baum natürlich eine der effizientesten Möglichkeiten, aber solch einen hast du hier einfach nicht.
Ach wisst ihr was: sollte der Shop zu langsam werden, implementiere ich ladebalken für längere vorgänge, es ist spannend zuzusehen wenn etwas passiert. Man freut sich auf so ein "Progress".
Man kann ja auch Datensätze auf die ganz lange nicht zugegriffen wurde in eine andere Tabelle archivieren.
Früher war das vllt. noch "in", mittlerweile will der Nutzer seine Antwort am liebsten in Echtzeit, also auf deutsch: sofort.
Vorallem in der Wirtschaft (z.B. Shop) kostet sowas viel Geld und da du einen Shop bauen willst, würden die Nutzer vllt. lieber zu einem anderem Shop wechseln, weil ihnen die Suche einfach zu lange dauert. Selbst bei Amazon dauert die Suche für meinen Geschmack schon etwas zu lang, aber bei der Datenmenge, die sie durchsuchen müssen, ist das was ganz anderes.
Man kann ja in SQL auch Views definieren. Werden diese gecached? Vllt wäre das eine Möglichkeit virtuelle Tabelle zu generieren auf die dann schnell zugegriffen werden kann.
Man kann ja in SQL auch Views definieren. Werden diese gecached? Vllt wäre das eine Möglichkeit virtuelle Tabelle zu generieren auf die dann schnell zugegriffen werden kann.
Views sind auch nur virtuelle (vermutlich nur im RAM gehaltene?) Tabellen.
Überlass solche Optimierungen lieber MySQL selbst - die wissen (hoffentlich) schon, was sie da tun.
Außerdem kannst du dein Memory Limit in der Konfiguration so anpassen, dass MySQL von selbst Queries (Abfragen) cachet.
# löschen eines Datensatzes in einer normalen, relationalen DB, Löschweritergabe (On Delete Cascade) über FKs
DELETE FROM Category WHERE primaryKey = ?
Java:
// löschen eines Datensatzes in deiner Tabellenstruktur mit Löschweitergabe (On Delete Cascade)
void delete(int itemId) {
int[] childIds = SELECT primaryKey FROM Category WHERE parentId = :itemId
for (int childId : childIds) {
delete(childId); // rekursion
}
DELETE FROM Category WHERE parentId = :itemId
DELETE FROM Category WHERE primaryKey = :itemId
}
Du brauchst uns nicht erzählen, dass deine Methodik einfacher wäre. Im Gegenteil; mit deiner Methode bekommt man ekelhafte enge Bindung zwischen hardcore Logik-Code und der DB, Wartbarkeit = 0.
Ich freue mich, dass ich von einem Datenbankexperten so einen Wertvollen Tipp erhalten habe!
B
Bitte was? In welcher Realität lebst du?
SQL:
# löschen eines Datensatzes in einer normalen, relationalen DB, Löschweritergabe (On Delete Cascade) über FKs
DELETE FROM Category WHERE primaryKey = ?
Java:
// löschen eines Datensatzes in deiner Tabellenstruktur mit Löschweitergabe (On Delete Cascade)
void delete(int itemId) {
int[] childIds = SELECT primaryKey FROM Category WHERE parentId = :itemId
for (int childId : childIds) {
delete(childId); // rekursion
}
DELETE FROM Category WHERE parentId = :itemId
DELETE FROM Category WHERE primaryKey = :itemId
}
Du brauchst uns nicht erzählen, dass deine Methodik einfacher wäre. Im Gegenteil; mit deiner Methode bekommt man ekelhafte enge Bindung zwischen hardcore Logik-Code und der DB, Wartbarkeit = 0.
Das tut mir leid. Ich meins nicht wirklich böse Aber mir geht beim besten Willen nicht in den Kopf, warum du so starrhaft versuchst, ein Problem mit einem Werkzeug zu lösen, das dafür nicht ansatzweise geschaffen ist.
Das tut mir leid. Ich meins nicht wirklich böse Aber mir geht beim besten Willen nicht in den Kopf, warum du so starrhaft versuchst, ein Problem mit einem Werkzeug zu lösen, das dafür nicht ansatzweise geschaffen ist.
Das kann ich dir beantworten. Wenn ich einen Nagel in die Wand hauen muss um ein Bild aufzuhängen, aber nur eine Zange habe, dann verwende ich die eben als Hammer so gut es geht.
Allerdings ist das was hier abgeht eher damit zu vergleichen, das ich ein Bild aufhängen muss aber keinen Nagel besitze. Dafür aber ein Tesastrip (oder wie die auch immer heissen) und ich nun versuche diesen Tesastrip in die Wand zu schlagen um das Bild dran zu hängen
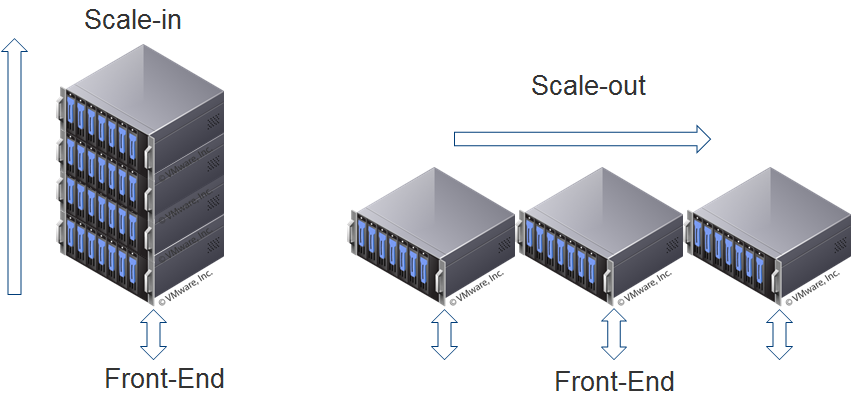
Ich meinte mit Skalierbarkeit in diesem Fall scaling out, also dass die Datenbank auf mehrere Server aufgeteilt wird (z.B. Google BitTable Technology). Das funktioniert bei MySQL aufgrund der Abhängigkeiten (z.B. INDEX, AUTO_INCREMENT usw.) nicht ganz so gut.
Diese Benchmarks sind aber nur für einen Server gedacht, also scaling up und nicht scaling out.
Wenn du dem Server mehr RAM und mehr CPU Cores gibst, kann er natürlich mehr Verbindungen handeln, aber irgendwann wird das extrem teuer, weshalb man lieber auf mehrere, verteilte Server, statt auf einen Super Server setzt.
Hier mal 2 Abbildungen, die den Unterschied sehr gut aufzeigen:
Vllt. weißt du jetzt, was ich mit scaling out meinte.
Erstens mal, wenn du solche Performance-Anforderungen hast dann hast du auch die fetten Server. Und zwar nicht nur einen.
Und zweitens meinte ich deshalb auch mehr diesen Absatz:
Many of the world's most trafficked web properties like Facebook, Twitter, Zappos and Zynga rely on MySQL performance and scalability to serve millions of users and handle their exponential growth. MySQL Replication is the most popular and cost-effective way to deliver performance and scalability. MySQL Thread Pool provides added scalability benefits in MySQL Enterprise Edition.
Edit: also Replication bringt das was du als scale out bezeichnet hast.
Erstens mal, wenn du solche Performance-Anforderungen hast dann hast du auch die fetten Server. Und zwar nicht nur einen.
Und zweitens meinte ich deshalb auch mehr diesen Absatz:
Many of the world's most trafficked web properties like Facebook, Twitter, Zappos and Zynga rely on MySQL performance and scalability to serve millions of users and handle their exponential growth. MySQL Replication is the most popular and cost-effective way to deliver performance and scalability. MySQL Thread Pool provides added scalability benefits in MySQL Enterprise Edition.
Edit: also Replication bringt das was du als scale out bezeichnet hast.
Ich kann dazu fachlich zwar nichts sagen, habe aber schon öfter gehört, dass jeder DB-Anbieter es schafft, Benchmarks zu erstellen, aus denen sein Produkt als Sieger hervor geht. Kann mir nicht vorstellen, dass ausgerechnet DataStax, die ihr Geld mit Cassandra verdienen, wirklich neutral ist.
Ich kann dazu fachlich zwar nichts sagen, habe aber schon öfter gehört, dass jeder DB-Anbieter es schafft, Benchmarks zu erstellen, aus denen sein Produkt als Sieger hervor geht. Kann mir nicht vorstellen, dass ausgerechnet DataStax, die ihr Geld mit Cassandra verdienen, wirklich neutral ist.
Wenn du dir den Benchmark mal richtig angeschaut hättest, hättest du bemerkt, dass dieser von der Universität von Toronto stammt.
Datastax haben ihn lediglich auf ihre Seite kopiert.
Ehrlich gesagt habe ich ihn mir überhaupt nicht angeschaut. Zum Einen habe ich unter dem Link gar keinen Benchmark gesehen (die Seite sieht bei mir ziemlich unvollständig aus), zum Anderen glaube ich ohnehin, dass Probleme nur selten durch den Wechsel der DB gelöst werden können, sondern eher durch durch das hier beschriebene Verfahren.
Ehrlich gesagt habe ich ihn mir überhaupt nicht angeschaut. Zum Einen habe ich unter dem Link gar keinen Benchmark gesehen (die Seite sieht bei mir ziemlich unvollständig aus), zum Anderen glaube ich ohnehin, dass Probleme nur selten durch den Wechsel der DB gelöst werden können, sondern eher durch durch das hier beschriebene Verfahren.
Indexe machen WRITEs lahm, da sie sortiert werden müssen. Natürlich sind INDEXe das erste, was man machen kann, um READs zu optimieren. Aber FALLS man wirklich viele Daten (BigData) verarbeitet und damit auch schreibt, bringt so nen Index nichts.
Stell dir mal nen Spiel vor, dass auf MySQL setzt und ne Million WRITEs ausführt. Da würde ne MySQL Datenbank sicherlich schnell zusammen brechen.
Indexe sind Abhängigkeiten und müssen sortiert sein. Cassandra dagegen basiert auf Googles BigTable Technologie auf, da gibt es keine direkten Indexe mehr. Jeder Server sucht parallel und liefert das zurück, was er findet.
Aber wir sind vom Thema abgewichen, in diesem Thread ging es ja eig. um etwas komplett anderes.
Ne ist ok. Ich bin noch am experimentieren. Bei der Suche werde ich in den Attributen suchen also
SELECT * FROM CATEGORIES WHERE TYPE = "ATTRIBUTE_VALUE" AND VALUE LIKE "%SUCHWERT%"
TYPE wird auch im Index enthalten sein.
jeden Datensatz kriegt man dann in weniger als einer Millisekunde bei Z.B. 2^1000 Datensätzen. Daraufhin wird für jeden Datensatz geprüft, ob die Parent ID auf einen PRODUCT zeigt, was weitere (weniger als eine Millisekunde) Zeit benötigen wird (korrigiert mich wenn ich da falsch liege). Man könnte auch für bessere Performance eine spalte namens PARENT_TYPE einführen...
EDIT:
Ah, es kann ja sein dass "LIKE "%%"" zusätzliche Zeit benötigen wird.
Willst du uns verarschen ? Weiter oben hast du mal erklärt 2^1000 sei die Anzahl der Atome im Universum. D.h. du weisst zwar noch nicht wie du diese Datensätze abspeicherst aber du weisst dass du in weniger als einer Millisekunde jeden wiederfindest ?
Weiter oben hast du mal erklärt 2^1000 sei die Anzahl der Atome im Universum. D.h. du weisst zwar noch nicht wie du diese Datensätze abspeicherst aber du weisst dass du in weniger als einer Millisekunde jeden wiederfindest ?
Willst du uns verarschen ? Weiter oben hast du mal erklärt 2^1000 sei die Anzahl der Atome im Universum. D.h. du weisst zwar noch nicht wie du diese Datensätze abspeicherst aber du weisst dass du in weniger als einer Millisekunde jeden wiederfindest ?
Ja. Hypothetisch. Also wenn wir so einen Universum hätten (aber wer weiss es schon, keiner weiss was dunkle Energie ist)
und zwar ld(2^1000)=1000. Also bei einer binären Suche maximal 1000 vergleiche. Nehmen wir an wir vergleichen Integers. Moderne Rechner vergleichen 1000 Integers in weniger als einer Millisekunde.
Edit: übrigens: es soll weniger als 2^1000 Atome geben. Ich habe 2^1000 nur als Beispiel genannt.
Wurde ja oft gefragt: mit der Skalierung meine ich halt, dass man die Tabelle sozusagen dynamisch im der Breite anpassen kann. Deshalb Skalierung, weil man die Tabelle sozusagen ausdehnt (durch hinzufügen von Spalten) oder komprimiert (durch löschen von Spalten)
")